Scraping the MLB for Science & Glory
but mostly science... or math
If you’ve been following baseball long enough you might have noticed nobody likes baseball anymore, and everyone has an opinion or stance or view or insight into how to fix it.
As someone who likes baseball (and statistics), I want to analyze these trends myself and find out if I need a new “national pastime”, or if these charlatans are just talking out their …er… padding their word counts.
So for this essay, we'll begin a multi-step journey, analyzing baseball statistics collected from the MLB to analyze the cause of "baseball's declining fan base" in later essays.
The Plan
Just like landing on the moon, blind dates, or playing with data science, having a plan before you start is usually a good idea.
As for our plan, we'll need to define a scientific question from the internet's "opinions" about baseball's decline before we can find sources of information we'll use to answer it.
The Question
While there are literally TONS [1] of articles with opinions on "how to fix baseball", the main claim I want to answer is:
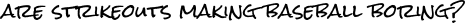
This question seems to have been asked every baseball season, or at least before I stopped searching the internet at a 1999 Chicago Tribune article interviewing Ted Williams about the rise in strikeouts with the "new wave" of power hitters like Mark McGuire and Sammy Sosa.
Which I get, if no one can hit the ball then baseball is really 9 dudes throwing the ball to themselves for 3 hours, which is boring.
So, with a solid question defined, let's start looking for sources of information that could answer it.
| [1] | "literally TONS" measured by page count from a google search, not by weight which the internet is estimated to only weigh ~50 grams or 0.00005 metric tons. |
What Data Do We Need
Our question is dealing with trends in pitching and hitting statistics. So we'll need to find a source of baseball statistics going back to the beginning of baseball (anno domini ~1876) or as far back as we can find.
While there are many websites to choose from, I feel the data from the MLB is a good choice, mainly so we can say "according to the official MLB data…" before we start arguing with strangers on the internet.
Unfortunately though, as is often the case, the MLB doesn't give us a link to download their statistics for further analysis.
So we'll need to build a "web scraper" to download the data directly from their website, essentially making our own "download" button.
Some Rules Before We Start
Before we begin collecting data from the MLB, I feel I should give a few words (warnings) about internet etiquette:
- Respect the MLB's terms and conditions. The MLB are savages in the box and can defy the laws of physics to destroy you if you mess with their copyright.
- Don't stress their servers. Our scrapers can easily make thousands of requests per second which their servers will struggle to fulfill. (See rule #1 for why)
- The code will break. Websites change their layouts like I change my …er… socks. Make sure you save the data you've downloaded so you only have to do this once.
Now with all the etiquette out of the way, let's start collecting some data.
Collecting Some Data
Back "in the day" this step would require "web scraping", using python libraries like BeautifulSoup, to parse the raw HTML for the data we want.
Now-a-days, with the increasing popularity of tools like AngularJS and RESTful APIs, websites are using JavaScript to render the web-page on our browsers (client-side) instead of on their servers (server-side).
The MLB is one of these "now-a-days" websites.

With a client-side app, the static HTML our browsers download is a template (skin) for the data. The JavaScript will download the data using the RESTful API and convert it into something we can easily read by applying the template.
As complicated as that sounds, because the data returned by the API is in a form our computers can use, it's often easier than scraping the web-page directly.
We just have to find the API.
Finding The Data
Because our browsers are doing all the work of building the MLB's client-side web-page, we can use our browser's built-in developer tools to find where the data is coming from.
Depending on which browser you prefer, open your developer tools:
- How to open Chrome's Developer Tools.
- How to open Firefox's Developer Tools.
With the developer tools open:
- Find and open the Network tab.
For Firefox 69.0 the Network tab is in Tools → Web Developer → Network or if you're into key bindings Ctrl+Shift+E.
- Next, go to the MLB's stats page and refresh the page with the Network tab open.
You should see a list of all the requests your browser made while building the MLB's web-page. Something similar to this (I'm using Firefox 69.0):
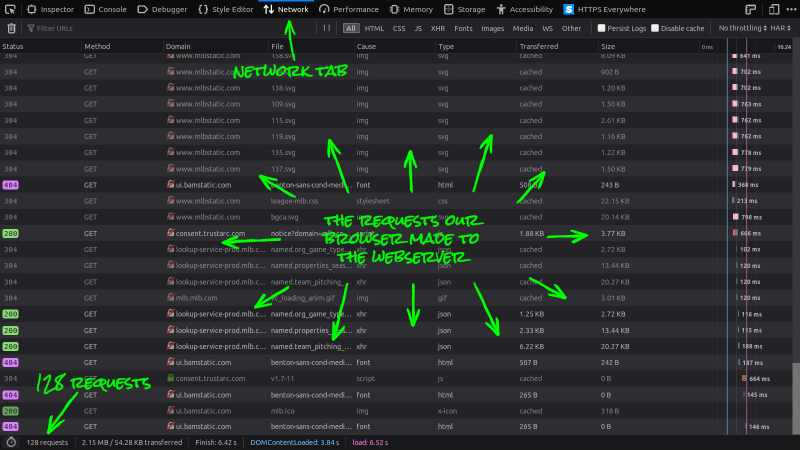
If you're in the year 2019, our browsers made 128 individual requests to their servers (54 more than average) for information to build the web-page. Which is 127 more requests I'm willing to look through by hand, so let's start filtering these requests down:
- Click on the XHR icon to filter out unrelated requests.
The requests we're interested in are XHR (XMLHttpRequest) objects. These are requests made by the web-page's JavaScript to get data (usually in XML or JSON form) from an API.
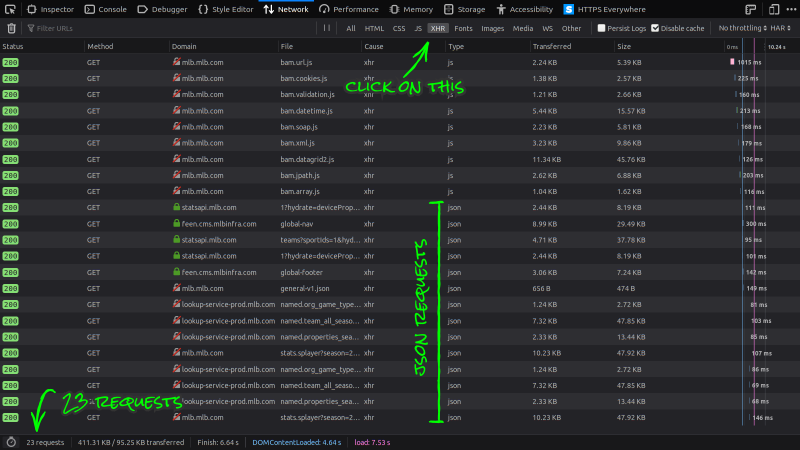
With the requests filtered, we can start exploring for the data we want. We know we're looking for data which usually comes in either XML or JSON format, so we can ignore the "js" types.
- Click on each Response looking for the data.
I usually look at responses with the largest size first and work my way down. After a few attempts, we'll find a JSON blob with keys that match the data we want.
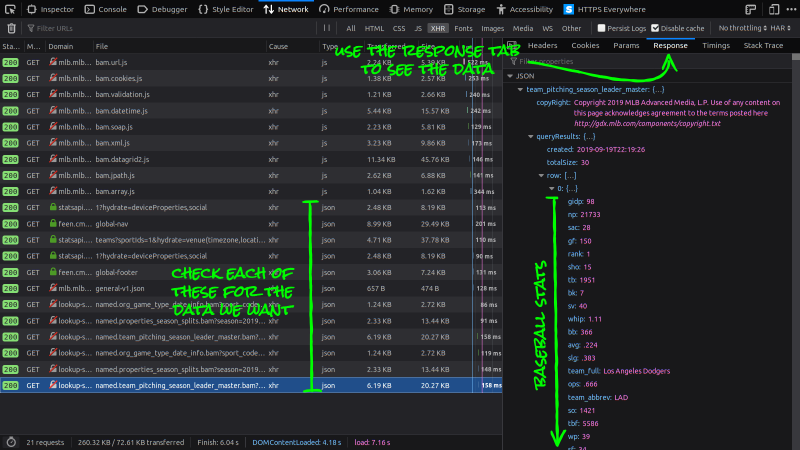
Huzzah! We've found the API endpoint with the data we need.
Before we move on, take note of the data's shape in the response. Notice the
list rows, with all the baseball stats, is inside queryResults
inside team_pitching_season_leader_master. We'll need this when we
start building the web scraper later on.
Our next step is to find how we can recreate the request using python:
- Switch to that request's Headers tab and copy the URL.
This will show us the URL and the Headers we sent to the server.
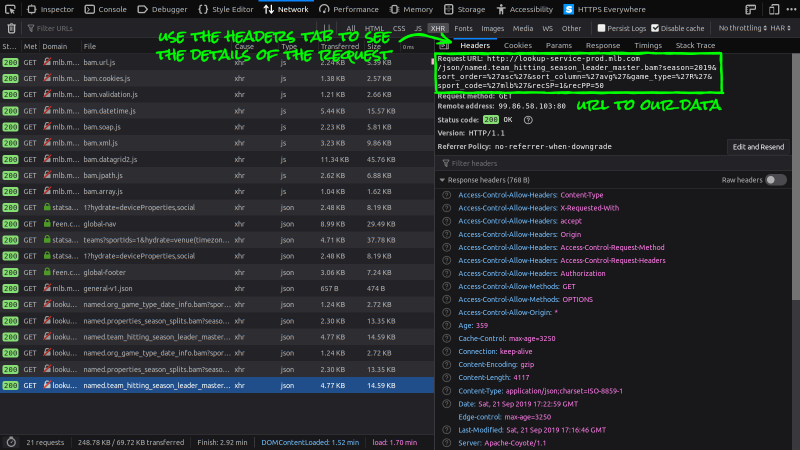
If everything went according to plan, when you
- Copy the URL into a new browser tab,
you should see the same information we found in the Developer Tools just a moment ago telling us we've found the URL to the API we want.
Good Job!
The Code
With the API discovered, we can begin building the web scraper to download the pitching statistics that will help us answer our initial question.
To make things easier on ourselves, let's install some libraries to help us download the data.
We'll be using:
- requests to create the HTTP requests to the MLB's API and return its content.
- and pandas to help us manipulate and analyze (data wrangle) later on, after we've downloaded the data from the MLB.
Both can easily be installed via pip like this:
$ pip install requests pandas
Writing the Code
From our exploration above, we know the URL to our endpoint is this:
team_pitching = (
'http://lookup-service-prod.mlb.com/'
'json/named.team_pitching_season_leader_master.bam?'
'season=2019&sort_order=%27asc%27&sort_column=%27whip%27'
'&game_type=%27R%27&sport_code=%27mlb%27&recSP=1&recPP=50'
)
However, this will only download each team's stats for the 2019 season. This API uses the query string parameters as a kind of filter for the content it provides to us.
For example, changing season from 2019 to 2018 would yield us each
team's pitching statistics for the 2018 season or changing game_type to
"%27S%27" will give us statistics on spring training games.
So let's break team_pitching down into its component parts, allowing
us to make requests for the different seasons the MLB has in their database.
We can start by separating the domain, path, and query string parameters into separate variables like this:
domain = 'https://lookup-service-prod.mlb.com'
path = '/json/named.team_pitching_season_leader_master.bam'
query_string = {
'season': 2019,
'sort_order': '%27asc%27',
'sort_column': '%27whip%27',
'game_type': '%27R%27',
'sport_code': '%27mlb%27',
'recSP': 1,
'recPP': 50,
}
After looking up what the %27 means (they're URL encoded ' apostrophes),
let's make our future selves happy by making a simple function to replace the
%27 (with a note) and turn our query_string into this:
# words are quoted with apostrophes
quote = "'{}'".format
query_string = {
'season': 2019,
'sort_order': quote('asc'),
'sort_column': quote('whip'),
'game_type': quote('R'),
'sport_code': quote('mlb'),
'recSP': 1,
'recPP': 50,
}
With our URL broken down, we can make a simple for loop to go through
each year (1876 - 2019), making a request to the MLB to download the pitching
statistics for that season and save the results into a list creatively called
data.
import time
data = [] # we'll save all the stats here
# go through each season and make a request
for season in range(1876, 2019 + 1):
time.sleep(1) # rule #2 don't hammer the servers
# update the query_string for the correct season
query_string['season'] = season
# make the request to the MLB
response = requests.get(
domain + path,
params=query_string
)
# raise an error if the MLB gives
# an invalid response back
response.raise_for_status()
# pull the list of stats out of the response
stats = response.json()[
'team_pitching_season_leader_master'
]['queryResults']['row']
# add the season to each row, and
# append it to our 'data' list
for team in stats:
team['season'] = season
data.append(team)
And finally, after we've collected all the data from the MLB, we put the data into a pandas DataFrame to start the "data wrangling" phase of our journey.
import pandas as pd
df = pd.DataFrame(data)
For now though, remembering rule #3 above, we'll save our data to disk and wait until we have more time to answer the question "Are strikeouts making baseball boring".
df.to_pickle('mlb-team-pitching-statistics.pkl')
Good Job Everyone!